
作者:广州大学 IStar战队
1、赛题理解和数据探索
拿到题后先看了一下数据,发现和常规的数据挖掘比赛有点不一样,这是一个类别严重不平衡的多分类题型。总体样本约 2w,标签数据只有一半的恶意域名数量,且不足五百, 却缺少正确标签的数据。第一问题是如何选取正常域名的标注数据,以及后续如何处理类别 不平衡的多分类的数据。 把全部表格数据合成一个表后,去除 encoded_ip 为空值的数据后的 fqdn 个数还剩 15780,约 1.5w,合并操作代码。(这里并没有对 flint 表合并,因为 access 的内容和 flint 有冲突
把全部表格数据合成一个表后,去除 encoded_ip 为空值的数据后的 fqdn 个数还剩 15780,约 1.5w,合并操作代码。(这里并没有对 flint 表合并,因为 access 的内容和 flin t 有冲突)
然后查了一下相关资料 了解到一些特征,

对域名的根域名以及对应 ip 的做了个切分操作,便于统计和交叉特征

在数据可视化阶段也观察到恶意域名相对于正常域名的活跃时间段存在明显差异
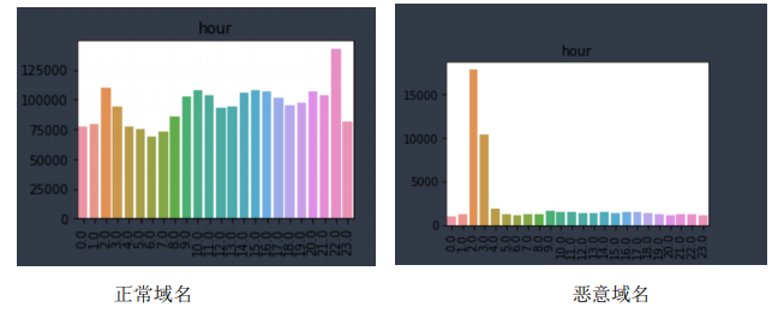
可知正常域名在每个小时的请求记录是差不多的,而恶意域名的在一天的某个时间段异常活 跃。
2、特征工程
1、 对 hour,minute,day,latitude,longitude,count 数值特征统计最大、最小,均值, 方差,中位数等特征
2、 对 isp、’encoded_ip、ip_tld、country、city、subdivision 做 nunique 和 count 特征,
3、 对’hour’, ‘day’, ‘count’,’longitude’,’latitude’ 做分位数特征,刻画不同时段的变化情况
4、对 encoded_ip’,’subdivision’,’country’,’hour’,isp’,’ip_tld’ ,’encoded_fqdn_first’等类别特征做 value_counts()统计,并对他们的’count’,’latitude’,’longitude’的数值统计刻画特征
5、类别交叉特征,提取不同类别的统计他们的共现次数、unique、熵、比例偏好的特征
6、将数据按时间排序后 以一个 fqdn 为一个文章,他的(ip_tld ) ‘encoded_ip 脱敏前缀作为 单词合并,统计 TF-IDF 、count 以及训练w2c 20 维的向量。
3、模型预测
对数据做完特征后,开始上模型了, 前面提到如何建立正常样本的标签,因为正常样本数量远远大于恶意,本次思路是利用 lgb 模型先把所有恶意域名看作一类,然后分七折抽取总体数据(约 1.5w)的六份作为测试数 据,另外一份作为正常样本,当作伪标签,来二分类训练,这样每次训练预测出来恶意样本 数量在四、五百多个,取在七份测试数据中 fqdn 出现次数达六次的 fqdn,当作恶意样本, 这个时候有 515 个恶意样本。现在再去和有标签的数据进行多分类预测。
第二部分 多分类预测恶意域名之间类别 还是用的 lgb 做了个多分类五折预测,利用标注好的 476 个域名训练模型来预测刚才的分 类出来的 515 个恶意样本。
4、总结
在这种数据小,类别严重不平衡的时候,模型预测有时效果不够优秀,由于时间原因, 后期完善还应加些专家经验,还有没使用的 whois 表加以验证结果,比单纯模型出的结果应该要好不少。
参考论文《Fast-flucos:基于 DNS 流量的 Fast-flux 恶意域名检测方法》
Comments are closed