
Coremail邮件安全竞赛writeup – ccgo团队
赛题一:火眼金睛
问题概况
请各参赛队伍了解常见的邮件安全协议,熟悉常见的邮件数据头部字段。在此基础上,自行设计检测算法,识别数据集中所有包含“发件人伪造(Sender Spoofing)”攻击行为的邮件。
解题思路
通过对常见邮件安全协议的学习,相关RFC【5321-SMTP、7208-SPF、6376-DKIM、7489-DMARC】的浏览,并结合文献[USENIX2020]的内容。更加了解了 DMARC,DKIM, SPF 等邮件安全协议,如 DKIM-Signature, Authentication-Results 等字段中各标志含义,总结出几条较为显著的识别发件人伪造的规则。
对本题较为重要的字段及其含义
- Authentication-Results字段中的spf, smtp.mail信息。
- 当spf=pass时,表示 该邮件发送域的spf记录允许其主机ip发送邮件,当spf为其他值时,无法肯定该邮件被允许发送,可能存在问题。
- smtp.mail 发件人地址
- DKIM-Signature字段中的 d 标志。
- d代表发件域的域名信息
- From字段信息
- 声称的发件人及发件地址,可伪造。比如本题数据集中某些攻击邮件中会含有两个@符号,目的就是混淆试听。
解题过程
根据上述字段含义,不难得到以下几条规则。
- spf != pass
- 找到的邮件有 [184, 313, 609, 779, 1753, 2047, 2052, 2214, 2266, 2417, 2608, 3069, 3087, 3248, 3683, 3808, 3827, 3839, 4424, 4479, 4687, 4903, 5038]
- From字段中出现的邮件地址大于1个
- 找到的邮件有 [228, 272, 672, 946, 1083, 1267, 1304, 1386, 1439, 2328, 2416, 2708, 2819, 3177, 3649, 3839, 4370, 4706, 4893]
- From字段中通过base64解码出两个 ‘@’ 符号
- 找到的邮件有 [135, 903, 1037, 1170, 3255, 4291]
- DKIM-Signature d 域名与 From 域名不一致
- 找到的邮件有 [1345, 1534, 4402, 4537, 4607]
- smtp.mail 地址与 From地址不一致
- 找到的邮件有 [95, 470, 477, 925, 1002, 1122, 1209, 1216, 1252, 1311, 1388, 1395, 1444, 1492, 1753, 2001, 2035, 2063, 2102, 2332, 2439, 2753, 2773, 2908, 3069, 3090, 3152, 3421, 3461, 3537, 3579, 3838, 4193, 4267, 4306, 4345, 4428, 4479, 4614, 4625, 4722, 4860, 4932, 4998]
- From字段中有 ‘xn--‘ 特殊符号
- 本条规则是在 其他规则找到的攻击邮件中 进行总结发现的。
- ‘xn--‘ 可用于中文域名的编码,较为少用,有些客户端无法解析,可能会被攻击者利用来进行攻击。
- 比如4903.eml,实际字段: From: “Ashok Mundhra” mundhra@xn--iclou-2wf.com,但是outlook显示: Ashok Mundhra <mundhra@iclouԁ.com>。如图
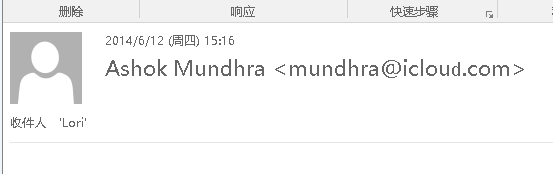
- 找到的邮件有 [779, 830, 1451, 1517, 1856, 1979, 2753, 2790, 4899, 4903]
- ‘\00’ 符号
- 含有’\00’符号用于获取公钥,DNS将’\00’符号看做分隔符,二者之间的歧义给了攻击可能的空间。
- [1209, 2102, 2908, 3461, 3537, 3579, 4306, 4428, 4479, 4614, 4722, 4860]
- 如图 1209.eml

- 此外,还尝试过sender != from 的规则
- 但发现其中有几条例外情况,比如 [1838, 1924, 1766, 1472]
- 这几封邮件的Sender中含有 ‘+’ ‘-‘ 等符号,干扰了本条规则的适用性。经查阅 ‘+’ 后面的字符会被略过。
赛题一总结
在本题中,我们接触到了很多异常的邮件头部字段的样本,大致理解了“发件人伪造(Sender Spoofing)”这类攻击行为,并在比赛的过程中加深了对邮件安全协议的理解。
赛题二:明察秋毫
问题概况
某家企业希望根据根据邮件内容类型的不同,采取差异化的邮件过滤策略。譬如在邮件服务器上直接拦截所有勒索欺诈类邮件,而对于一般的推广营销类邮件,则移入用户邮件的垃圾箱中。
为实现上述差异化的邮件过滤策略,请参赛选手分析邮件日志数据,设计分类模型,实现针对邮件类型的分类。注意:检测方法既可以是基于规则的,也可以是基于学习的。
本题数据集中的字段有
– @timestamp:时间戳
– attach:邮件附件名列表
– authuser:是否为本站用户
– content:邮件内容(前512字节)
– doccontent:Office类型邮件附件的文档信息
– dwlistcnt:命中域名自动白名单的rcpt数量
– from:信头的from信息
– fromname:信头的fromname
– htmltag:邮件包含的html tag
– ip:链接Coremail服务器的ip
– region:regionip的地理位置
– mid:邮件内投最终的mid
– rcpt:收件人email列表
– recviplist:信头的Received:提取的IP地址列表
– regionip:从信头提取的X-Orginal-IP之类的原始的发信人IP(而不是服务器IP)
– sender:发信人
– subject:邮件的主题
– url:邮件中包含的URL链接(可能包含手机号码/qq号码和其他一些非URL信息)
– wlistcnt:命中自动白名单的rcpt数量
– xmailer:信头xmailer信息
– licenseid:请求的客户端的licenseid
解题过程
先有鸡还是先有蛋?
要进行分类,就得首先知道数据的特征在哪,而要想知道数据的特征在哪,就必须先有一些已分类的样本。
这道题最直白的想法自然是利用subject和content对文本进行聚类,然后观察规律。聚类的代码见:2_cluster.py。其先将邮件的subject和content连接起来并去除无意义字符后使用SentenceTransformer基于distilbert的多语言模型进行句子嵌入,最后使用KMeans算法进行聚类。
由于前期我们并不知道数据集的类是多少,因此我们通过elbow method只能大致确定类的范围在5-7类之间。
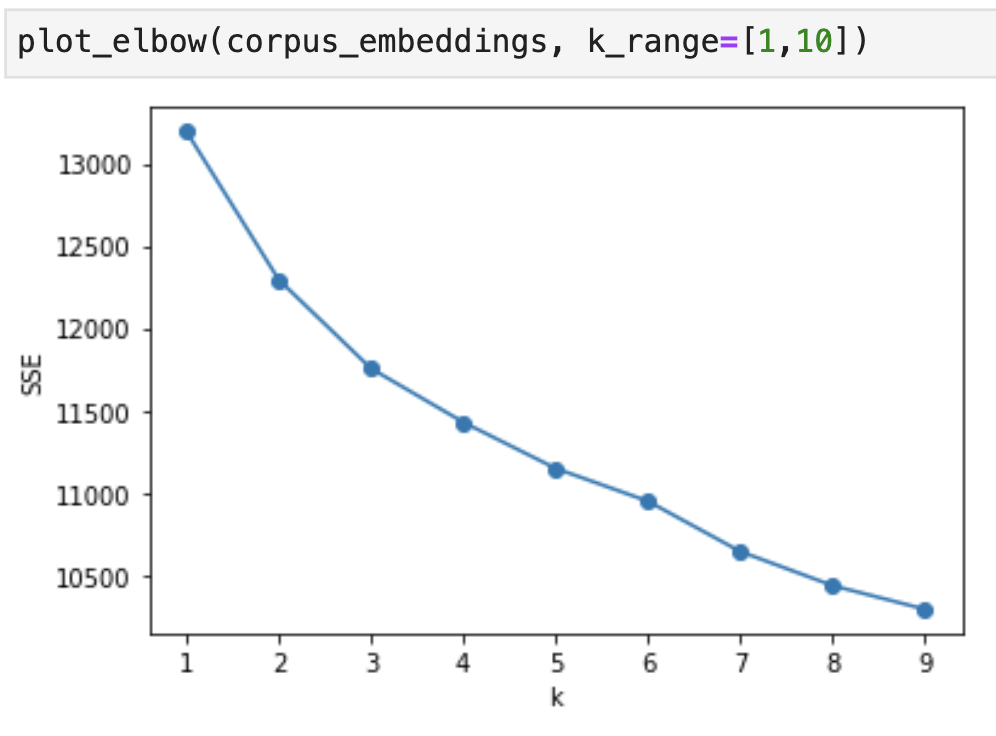
单靠文本相似度进行聚类有很大的缺陷,对于机器而言,最多只能把两段非常接近的文本聚在一起。因此一开始聚类的分数并不高。
先进行人工分类
在先有鸡还是先有蛋的困局下,必须先人工给一些邮件打上标签,了解数据,同时寻找特征。一开始随机选取了500多个邮件打上了标签。
初始选取的标签比较随意,分为以下五类:
1 发票 2 色情 3 赌博 4 广告 5 其他
发现强特征及使用
观察人工分类得到的样本,可以发现赌博类的邮件的发件人的xmailer都包含Microsoft Outlook IMO、包含同文件名的attach的邮件都是同一类型的、同一个发件人发的邮件都是同一类型的。
有相同的url也是一个不错的特征(这里的url依题目意思包含手机号码/qq号码和其他一些非URL信息,下文所述的url和题面一致),不过需要进行一定的预处理:
1. 去除url字符串中的收件人(如果包含该子串的话),这是为了方便后续根据url相同来判别是否为同一恶意邮件。
2. 去除2019和2020开头的数字串。
3. 对于https?://example.com/类型的也就是有效部分只有fqdn的链接,用alexa排名前100w的网站域名进行过滤,因为这些url和恶意邮件关联不大。
url字段的切分也有一定的讲究,该题所给的数据同一封邮件的多个url通过空格分隔开,分开后的每个子串,应当按照这种顺序进行判别:
微信 > URL > email > ip > 数字串
即:优先判别为特征更强的类型。
对数据的预处理和整理的代码文件见2_parser.py,其中将多值字段分开导出,这是为了导入数据库(1NF)。
这里我们主要是利用了四个强特征(比文本相似度要强):attach、xmailer、from、url。对于url,我们通过如图1所示的方式来给未知标签的邮件标上标签。
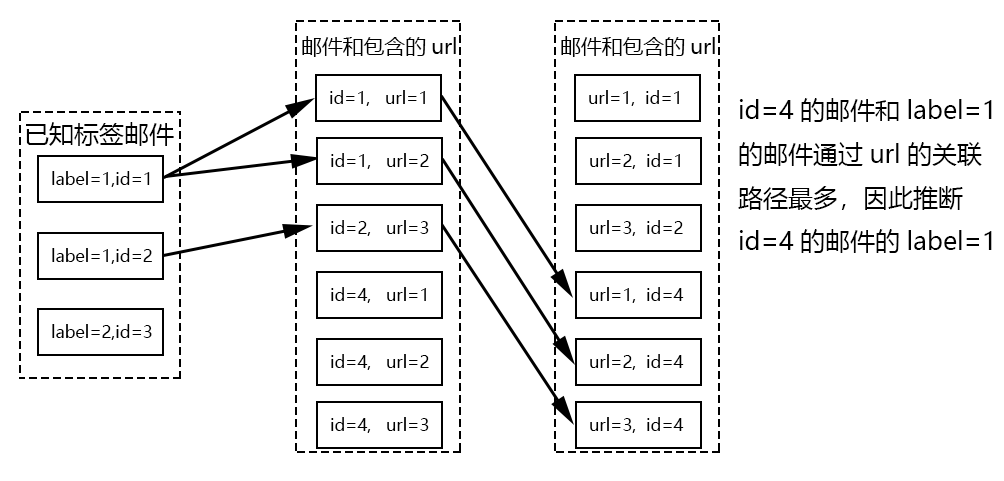
利用数据库联表查询很容易可以实现,具体代码见:
- 利用attach:“根据attach关联信息查找并插入表.sql”
- 利用from:“根据from关联信息查找并插入表.sql”
- 利用url:“根据url关联信息查找并整理成关联表格.sql”;“根据推断得到新id的记录数量来决定新id是什么标签.sql”
- 利用xmailer:“根据xmailer关联信息扩展.sql”
除去url的其他特征都为单值字段,利用数据库可以以类似方式实现,不再赘述。
利用初始人工标记的500多封邮件以及这些强特征,最终可以给接近19000封邮件打上标签。
基于文本相似度的聚类结果的巧妙使用
我们还剩下4000多封邮件还没有标记。这时候文本聚类派上了用场,因为我们这次并不需要直接将聚类结果用于提交,而只需要将文本相似度很高的少量邮件聚在一起,因此可以聚上百个簇,将聚类结果导入数据库,然后和利用url相似,对于未知标签的邮件,统计它所在的簇中数量最多的标签,具体代码见:“根据聚类结果推算剩下的邮件标签并输出结果.sql”。
上述过程存在一个问题:如果某个簇所有邮件的标签都未知,那这个方法不就失效了?
实际上,这正是一个可以巧妙利用的点。对于两封内容、发件人等种种信息都看似无关的邮件,机器是无法将它们联系到一块的,最开始的人工分类方式,实际上是在告诉机器“两个看上去不相关的邮件是同一类的”,而这种方式,就必然有所遗漏。那些已知标签很少甚至没有的簇,就是遗漏的需要人工标记的邮件。
这便是我们队解这道题的最核心思想:从机器的视角来看,它使用from、xmailer、url、attach、subject、content这些字段的相关性对邮件进行分类,然而机器无法揣测内容后面的真实意图,更无法按照人的思想对邮件分类,因此它按照自己的意思将24000封邮件分成几百上千个类,而人对那些机器无法分辨的邮件打上标签后,机器可以知晓人的意思,并最终按照人的意思给出分类结果。最开始人工标注的那部分邮件,我们称之为“种子”。
很自然的,我们希望种子能够尽量少但是又足够关键。利用聚类结果,我们可以快速提高种子的质量。首先,我们统计出那些已知标签较少的簇,具体代码见“寻找那些人工贴标签有所遗漏的簇.sql”。然后将这些簇中的少量邮件打上标签,并放到种子里。
基于文本相似度的分类
上面提到,我们用已知标签的接近19000封邮件结合文本聚类结果去计算剩下4000多封邮件的标签。然而这对于发票、色情、赌博这类邮件效果很差,因为这些邮件中的字符意义都非常隐晦,与正常的文本相悖,纯粹使用bert聚类实在是有点力不从心。为了提高这些邮件的分类精度,我们将已知标签的邮件的subject和content作为语料库,使用jieba进行分词并使用Tokenizer转换为向量,训练CNN之后对剩下4000多封邮件的类型进行预测。具体代码见Text-Classification文件夹。
树的培育
在一至五节中,我们将人工预分类的种子逐渐培养成覆盖整个数据集的大树,主要过程都已说明,综合来看树的培育过程如图所示:
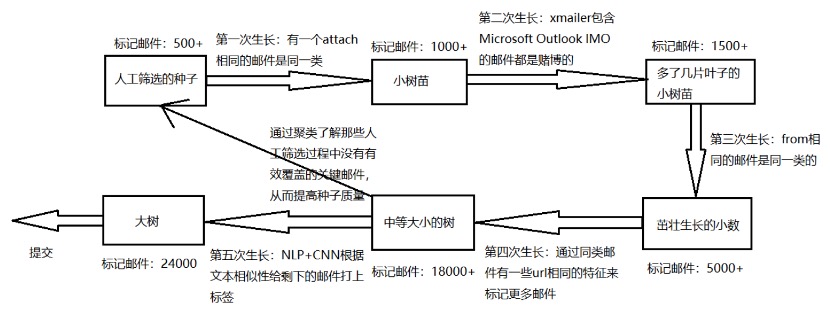
利用图中所示的方法,后来我们又人工给150~200封邮件打上了标签,最终结果的精度可以达到很高的水平。
这道题最尴尬的是:可能你培育出了一棵很好的苹果树,但答案要的是橘子树。。。
邮件的分类是一个很主观的事情,很无奈,我们无法知道最终答案是怎么样的,只能按照自己的感觉和主办方给出的分数反馈来进行调整。好在,我们只需要调整种子就可以改变最终答案了,因为这道题的答案在一定程度上受人的主观性影响,所以我们这种方法调整起来还是很有优势的。
split seed文件夹中有我们用来对种子进行细分的代码,利用它我们将当前同一类的邮件分成两类,而合并的话只需要把两类邮件的标签改成一样的就行了,就这样,我们慢慢的拆分和合并邮件,调整种子,缓步的提高成绩。我们提交的最高分的分类方式是:
- 开发票+做账报销
- 色情邮件(仅中文,不考虑英文)
- 商业推广+培训班+消息推送+拆红包领红包+大赛报名+学术推广+邀请投稿+保发SCI
- 仅有一条不明连接+伪造通知+恐吓+钓鱼
- 英文的约会、发照片、奇奇怪怪的网站+不明通知
至于答案的计算方式,我们使用了一个七分类的种子(见seed.csv),把24000封邮件分成七类后,进行了一些调整得到了上述的五分类结果,调整的方式如下:
最终答案的标签1 = 原1
最终答案的标签2 = 原2-所有英文邮件
最终答案的标签3 = 原7+原4
最终答案的标签4 = 原6
最终答案的标签5 = 原5+原2中分离的英文邮件
对七分类结果进行调整的代码见“最终调整.py”,运行时需要在代码根目录下放入文件主办方提供的环境中原来的“spam_email_data.log”。
赛题二总结
我们方法的优势在于,通过改变初始“种子”即可使得模型学习并检测新的样本,其实用性和模型迭代能力较强。在实际应用中可以将该模型和用户的邮件举报系统对接,进行在线学习(online-learning),当有新型威胁邮件被用户端识别并举报后,就能为模型提供新的“种子”,从而使得模型快速迭代更新,以适应日益变化的网络环境。
此外,还有一些工作在最终的解题思路中被放弃了,但也体现了一些我们的思考和尝试,比如我们利用关键词和fromname字段进行文本分类,同时针对最后纯靠pre-train的bert聚类对剩下的邮件分类效果差的问题,可以用我们已经训练好的样本对bert进行fine-tuning,之后利用其来预测难以区分的样本。此外目前我们主要使用了文本、内容类的特征,如果引入其他独立的特征进行综合研判模型效果应该会更好,如引入html tag特征、白名单相关的特征以及时序特征等。
赛题三:孤胆猎手
问题分析
在真实的企业网络环境中,一些攻击者总能想方设法绕过邮件检测引擎,使攻击邮件抵达员工的收件箱,最终达到窃取用户登录凭证等目的。与此同时,企业网络安全管理团队的精力十分有限,不可能实现对企业的全部邮件进行逐一审查。如果你是一家企业的邮件安全负责人,能否基于数据分析,利用长达三个月的企业邮件服务器日志摘要信息,设计检测模型,输出一批威胁程度较高的邮件,以便于后续的人工审查。请注意:检测模型不允许使用第三方威胁情报,检测系统必须能够离线运行。
本题数据集中的字段有
– rcpt:收信人邮箱地址
– sender:发件人邮箱地址
– ip:企业邮箱用户登录ip
– fromname:发信人名称
– url:直接从邮件正文、subject、附件、fromname中提取出来的url
– @timestamp:时间戳
– region:企业邮箱用户登录ip所在地区
– authuser:发信时False,收信时True,注意企业邮箱域内互发的话是只有一条发信记录
– tag:邮件编号,提交答案需要用到
解题思路
通过题目描述可大致推测检测目标主要是钓鱼邮件,因此在本题的数据集中,url应该是区分邮件类别的关键信息。通过选取部分url验证可以发现,数据集中混杂有钓鱼网站、spam垃圾邮件、恶意网站、邮件列表推广等,所以本题的得分点一方面在于检出尽可能多的钓鱼类邮件,另一方面应该是要尽可能把威胁程度较高的邮件(如窃取用户登录凭证的邮件)与其他类别的区分开。
相对于第二题而言,本题可用的学习语料较少,因此我们主要是基于经验观察恶意邮件日志样本,对日志数据进行分析挖掘可用的特征,并利用组合规则对邮件进行分类。
解题过程
从题目中描述可以了解,本题的用意是找到窃取用户登录凭证邮件,从攻击方式可知这类邮件中企业用户一般为收件人,因此我们推测这类高威胁邮件应主要分布在authuser=False的记录中。下文所有提交结果均为与authuser=False的记录做交集之后的结果。
特征1:fromname/sender_tld
首先我们先从发件人入手。考虑到钓鱼邮件的特征,很可能会通过构造一些欺诈性的名称字段 (fromname) 诱骗用户点击,例如:['administrator', 'admin', 'manager', 'boss', '经理', '管理员', '安全'],一些邮箱后缀名 (sender_tld) 也可能有引导性的关键字,例如['domain-admin.com', 'admin.com', ...]等。因此通过设计fromname黑名单,应该可以检测出一部分高威胁样本。
我们统计了数据集中fromname并未被加密的字段以及sender_tld字段,筛选了一批关键词设计了黑名单。
blacklist_fromname = ['administrator', 'admin', 'manager', 'boss', '经理', '管理员', '安全']
blacklist_tld = ['domain-admin.com', 'support.com', ...]
我们最初考虑是否把master加入blacklist_fromname,但是通过分析数据集发现,master关键词会命中fromname为postmaster的记录,虽然其中有较多的疑似钓鱼邮件,但同样也带入了较多的白样本,因此我们将master剔除。
我们筛选出了命中blacklist_fromname与blacklist_tld的记录进行并集并提交。
- result1: 0.334972 / 未统计条数
特征2:url
第一版本的结果一般,我们推测应该是有很多误判导致。接下来有两条方向,一方面要减少数据集中的误报,另一方面要涵盖更多高威胁邮件样本。
我们开始从url入手,通过观察数据集发现,很多rules1筛选的数据中,url都会带有类似"index.php?email="字段,我们推测这可能是获取用户邮箱信息的钓鱼链接。因此我们将该字段作为关键词对url进行筛选。
blacklist_url = ['index.php?email=']
由于blacklist_url筛选出的记录数量较多,因此我们将blacklist_url与blacklist_fromname命中的记录取了交集进行提交。
- result2: 0.426252 / 4618条
特征3: sender
该版本相比于上一版有比较明显提升,我们希望横向扩展一下数据集。我们推测钓鱼邮件发送者一般会群发邮件,因此现有检出记录中的sender可以认为是可疑账户。我们查询了rules2找记录的sender list,并将该sender list发送的全部邮件检出进行提交。
- result3: 0.385473 / 7605条
特征4: url进阶
result3的效果并不理想,我们核验了数据集发现很多新增加的sender发送的邮件中并不包含url链接,因此可能并未被认为是钓鱼邮件。但是从结果分数的变化来看,即使剔除这些url为空的记录,对于分数的提升也不大,该特征可能并不是显著的特征。
我们继续回到url分析,这次我们并未将blacklist_url与blacklist_fromname取交集,而是直接将blacklist_url筛选出的记录进行提交,这样做的目的是为了验证一下blacklist_url和blacklist_fromname这两类特征各自的显著性有多高。
- result4: 0.478011 / 14082条
特征5: url domain
result4的效果相比于之前版本又有了较大的提升,但是该特征能够过滤出14082条数据,从分数的变化来看,其中应该有超过半数都不是黑样本,我们还需要进行裁剪。
我们又从域名入手,相比于sender特征,我们认为域名更加能体现一个链接是否为钓鱼链接。我们观察了result4中对应的样本,发现其中存在一些高频出现的域名并不属于我们熟知的网站及服务,其中大部分网址无法访问,且url链接中夹杂很多奇怪的参数获取字段,我们筛选出一批url域名设计了黑名单(blacklist_domain)。
blacklist_domain = [
'power-h.net',
'conference.unila.ac.id',
'email.mg.appoderado.cl',
'click.pstmrk.it',
...
]
我们筛选出了blacklist_domain命中的记录并进行了提交。
- result5: 0.537727 / 6698条
特征6: ip / url参数再分析
基于blacklist_domain的结果取得了目前为止的最高分,我们又尝试将url域名进行扩展,比如和blacklist_fromname/blacklist_url进行交叉比较,但是结果都不是很好。我们团队讨论了一下,认为blacklist_domain虽然在实践中是一个实用性较强的方法,但是也许并不能完全符合比赛的要求。主要有两方面原因:
- 通过我们人工识别设置域名黑名单可能也会存在误判,因为钓鱼域名对应的链接与其他垃圾邮件发送、产品营销、恶意软件及代码传播中常用的域名、链接等很相像,较难区分。比较容易判断的一般是鱼叉攻击,即仿冒官方网站等,但我们并未在数据集中发现这类黑样本。
- 如果通过已知域名黑名单进行判断,可能会违反比赛主办方关于不允许用第三方威胁情报的限制。
因此接下来我们并未继续对域名做深入分析,转而进行新特征的探索。目前我们想到的还有两个切入点,即url特征的再分析,以及ip特征。
我们认为ip应该也是一个比较显著的特征,本题数据中保留了子网关系,我们希望更多的利用网段的关联性。我们并未尝试ip黑名单的方法,因为sender特征的不理想让我们意识到,直接从发件源进行筛选可能会有较多的误判,需要结合更多的特征来辅助判断。我们推测钓鱼邮件发送者的发送模式应为从同一ip/sender下给多人发送邮件,且其持续时间应在一定时间窗口内。该规则需要两个参数,一个是同一ip/sender发送邮件的收件人数量(RCPT_MIN),另一个是该ip/sender持续发送邮件的时间窗口(DAYS_MIN),我们通过调参、交叉筛选得到合适的设置如下:
RCPT_MIN = 35 # 最小收件人值(单位:人)
DAYS_MIN = 8 # 最小时间窗口(单位:天)
通过观察数据集发现,url中还包含很多企业邮箱尾缀(【ba7f5de13c9b54a0】)混杂在内的情况, 如:
http://itsforyou.su/?email=emota@【ba7f5de13c9b54a0】&s1=lvlv1&s3=mix
考虑到本题面向的问题主要是“抵达员工的收件箱”, “窃取用户登录凭证”,因此我们认为这种记录相比于不包含企业邮箱尾缀的url更有可能是钓鱼链接。此外这个例子也提醒我们基于index.php?email= 这一条件筛选可能无法覆盖到全部的黑样本链接,该过滤条件也应该进行宽松调整,我们调整为mail=这一条件。
综上,我们需要考虑的规则已经较为复杂,根据pandas的filter进行过滤可能较为臃肿,因此我们使用了yara包管理这些规则,上述规则对应的代码段如下:
rule3 = '''
rule rule3_count_sending : rule3
{
meta:
Author = "ccgo"
Description ="authuser=false, url里有mail=字样,且含有企业邮箱后缀【ba7f5de13c9b54a0】,且同一个ip/sender下发送的目标数量很多,时间较分散"
Description2 = "not include spam? 不能含有subscribe关键字 "
strings:
url_1 = /url.{1,2000}mail=.{1,40}ba7f5de13c9b54a0.{1,2000}fromname/url_2 = /url.{1,2000}subscribe.{1,2000}fromname/
authuser = /authuser.{1,5}false/ip = /ip.{1,50}region/
timestamp = /timestamp.{1,200}tag/rcpt = /rcpt.{1,200};/
tag = /tag.{1,5}\d+/
condition:url_1 and not url_2
andauthuser
and timestamp andip and rcpt andtag
}
'''
上述版本即为我们最终提交的版本。
- result5: 0.5769057285 / 9906条
总结
由于比赛时间较为紧凑,很多可能的解题思路我们并未完全实现,在此一并进行总结,也希望能和主办方及其他参赛团队进行探讨、思考。
基于自然语言处理的方法
本团队参加第二题的经验可以说明,基于内容的方法对于识别这类钓鱼邮件应该也会有较好的帮助,如结合subject和content字段进行综合分析,能够提供更充分的信息,对于模板式的钓鱼邮件攻击会有较大的帮助。
还可以利用自然语言处理方法对url字段进行分析,先归纳出一部分初步确认为钓鱼的url,引入迁移学习模型将这些url作为语料映射为嵌入向量,进行相似度分析和聚类比较,对各簇内url进行分析,找到钓鱼链接的相似特征。通过这类学习方法构造的模型,一方面会有更强的泛化能力,另一方面能够为基于规则的过滤系统提供特征选择的建议。
应对外部威胁情报受限困境
本题的限制条件是不允许用第三方威胁情报,并可以离线运行。经我们测试,通过加入域名黑白名单,是肯定可以提升得分的。我们对做这样限制的理解是,这是真实场景中的需求,因为威胁情报过于依赖主观判断,且有很大的延迟。
在不使用外部威胁情报的条件下实现钓鱼类邮件的判断难度较大。对一个url是否为钓鱼链接,我们之前做过这方面的探索,如2019年朱瑞同学的硕士论文《基于海森矩阵和图像哈希的鱼叉式钓鱼邮件识别算法研究》,基本思路是把url对应的网页生成截图,然后在图像层面进行相似性分析。在实际场景中,这应该是解决威胁情报困境的一个有效方法,不过在此题中不适用,因为题目数据里的url很多无法访问,且要求可以“离线运行”。
其他可能特征的思考
本题中,由于主办方保留了ip地址字段的子网关系,我们也希望能利用这一特征进行探索。基本假设是同一个子网内包含较多ip的同一发件方是钓鱼攻击者的可能性较低,原因有两方面。一方面是从攻击成本上考虑,钓鱼邮件攻击者不太可能控制一个网段太多的机器;另一方面是很多企业账户也有相似的通知发送机制,基于这一规则很容易误判。
因此可以同时统计以下字段综合构造特征:
- 发件人ip所在的子网一共发送的目标rcpt数量
- 此子网下发送过这类邮件的ip数量
- 持续发送邮件的天数
另外从社会工程学理论的角度分析,被简单伪装欺骗就上当的人更容易继续受骗,因此非APT类的钓鱼邮件中不应该出现太复杂的sender绕过机制,其目标人群主要是易受骗人群。我们发现url里面还有一些特征可以作为白名单的参考,比如含有subscribe/unsubscribe等关键字的大概率是邮件列表之类的推广邮件。
致谢
在本次比赛中,我们团队深入了解了邮件安全领域中经常面临的一些问题,锻炼了解决实际问题的能力,这对于我们的科研、学习之路是难能可贵的经历。在这里,我们要感谢本次比赛的主办单位——清华大学、Coremail论客以及datacon平台 。
主办方为我们提供了大量贴近于企业生产环境下的真实数据、应用场景以及实操环境,给我们提供了真实场景中进行锻炼的宝贵机会。无论从赛题的设计上,还是在比赛的组织、运营过程中,主办方都体现了极高的专业素养和专业的工作态度,积极解答、解决选手遇到的各类问题,在此再次感谢主办方的辛勤付出,希望datacon系列赛事越办越好!
ccgo团队
Comments are closed